DALL-E 2: Open AI’s Astonishing New Image Simulator
DALL-E 2 allows users to input descriptive phrases and in turn, the OPEN AI technology creates realistic images based on the described text.
This article is more than 2 years old
When DALL-E was introduced by OpenAI in January 2021, it was a revelation. The AI program, designed to use a version of GPT-3 to generate digital images from descriptions using natural language, was a hit from the start, even if some of the images it created were visually a little off-putting and, quite frankly, scary. Although we say that in jest (for the most part), OpenAI has continued to refine DALL-E and has now introduced DALL-E 2.
DALL-E 2 CREATES REALISTIC IMAGES LIKE NOTHING SEEN BEFORE

DALL-E 2 is OpenAI’s newest AI model. If you have seen the original DALL-E, then you know what you’re in store for, only this time OpenAI promises much better results visually. For those of you who are not as familiar with the DALL-E 2, or the original for that matter, DALL-E 2 takes sentences and descriptions and creates images from those. In comparison to the original DALL-E, the newer version is actually smaller in size but creates 4x better resolution images.
USERS INPUT PHRASES THAT THE TECHNOLOGY USES TO CREATE A REALISTIC IMAGE
We will try desperately not to get lost in the weeds here as we describe how DALL-E 2 works. The simple explanation of what DALL-E 2 does is that it takes the words you input and turns them into images. They do this as a two-part model using a prior (model) and a decoder.
By linking together both models (prior and decoder), DALL-E 2 brings to life an image. You simply input your sentence or description into a box in the program and out comes what we hope is a well-defined image. You can get quite imaginative with DALL-E 2, and the more descriptive, the better.
The decoder that this AI program uses is called unCLIP. If you know what the original CLIP model is, well the unCLIP works the opposite. UnCLIP will create an original image (embedding) based on a generic mental representation instead of what CLIP does, creating a mental representation from an image.
Here is an easier (we hope) way to think about it if the prior model, decoding, and embedding didn’t work. Visualize (you can even grab a pencil and piece of paper for this) a pond with a duck floating in it and the sun high in the background. Right there is the human equivalency of image embedding.
You aren’t sure what that drawing will eventually turn out like, but in your mind, you know what it should look like. A prior model is this – taking this sentence you put in your head to its mental imagery. Next up is for you to unClip.
Now you will want to start drawing. Taking this mental image and putting it down on paper is what unClip does for you. How close to your mental image is your final drawing?
So, what if you were to draw another with that same duck on a pond with the sun high in the background caption? Would it look the same as your first creation or would there be slight (or more) differences? It might look the same, but there is a good chance it won’t.
Look at your final image “duck on a pond with the sun high in the background.” Understand which of the drawn features best represents the image and which best represents the sentence. This is the process CLIP goes through when encoding your created sentence.
DALL-E 2 RESULTS OFFER MULTIPLE VARIATIONS
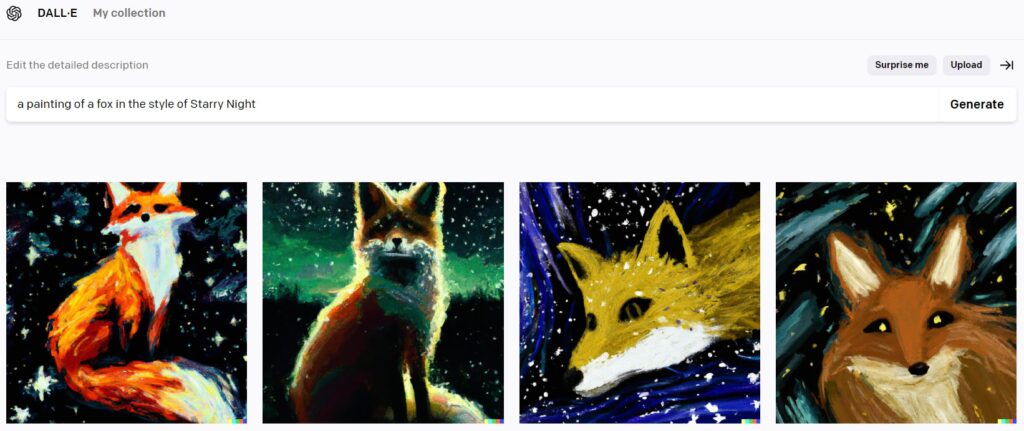
The beauty of DALL-E 2 is that you won’t always get the same result with the same caption (description sentence). There will be a lot of consistencies, but there will also be some subtle changes that can make for some interesting results as well. An example given is “a painting of a fox in the style of Starry Night” (yes, you can get that detailed with DALL-E 2).
You can take a peek at other results of here. What you see here are ten variations of one sentence. Some things are consistent. However, they all appear differently in each version.
Sam Altman (along with Elon Musk) is one of the founders of OpenAI and he took to Twitter asking for DALL-E “ideas” and asked his followers to reply with a caption. From that, he said he would generate around 20 or so.
Then Altman responded to his own tweet with another claiming that “these work better if they are longer and more detailed.” This tells you just how far DALL-E has improved with DALL-E 2. It is also saying that simple sentences or captions return worse results because they are too general for DALL-E 2.
So, Ryan Petersen (Co-CEO of Flexport) took Altman up on his suggestion with this: “A shipping container with solar panels on top and a propeller on one end that can drive through the ocean by itself. The self-driving shipping container is driving under the Golden Gate Bridge during a beautiful sunset with dolphins jumping all around it.”
The results hit just about everything Petersen captioned. DALL-E 2 grabbed almost everything Petersen asked for except for the dolphins. He didn’t even put it all in one sentence.
DALL-E 2 SOMETIMES TAKES PHRASES TOO LITERALLY
Regardless of the caption you create, DALL-E 2 will produce. It has been said often that “imagination is the limit,” but by seeing the results DALL-E 2 has produced, imagination isn’t the issue. But this is AI and while it’s growing by leaps and bounds, it has a certain lack of common sense to it.
For the most part, DALL-E 2 end results look fantastic. Sometimes, though, they lack the true human creation. Sometimes the pictures are too perfect, something you wouldn’t see in the real world. Sometimes, the pictures become too literal.
In one example, a caption read “a close up of a hand palm with leaves growing from it.” The picture generated by DALL-E 2 was precise as it showed two hands together with a plant growing from them. But what it didn’t do was understand to separate the hands, they appear fused together.
Another limitation seen with DALL-E 2 is that it can be, quite frankly, terrible at spelling. It appears that DALL-E 2 doesn’t encode the spelling from whatever text it reads in the dataset images. Therefore you will oftentimes see simple words badly misspelled.
So, if you are keen on trying out DALL-E 2, keep this in mind. You might get results that are too perfect or you might get results that are too literal and misspelled. You may also get results that will simply blow you away with imagination.
CONCERNS OVER STEREOTYPES, INAPPROPRIATE IMAGES, AND DEEPFAKES
There are a number of social aspects that have become a concern with AI programs such as DALL-E 2. For now, biases and stereotypes are some of the concerns seen with the techonology. An unspecific prompt will show people and environments as white and Western while gender stereotypes prevail (builders are men while flight attendants are women).
Explicit content is another major concern. OpenAI has a violence policy that wouldn’t allow for something like “a dead elephant in a pool of blood” but we know everyone finds workarounds. “A sleeping elephant lying in a pool of red liquid” would probably get the results one was looking for.
Deepfakes are also a possibility and although they use GANs (a deep learning technique DALL-E 2 does not use), the problem is real. People could learn to use inpainting (which is what DALL-E 2 uses) to add or even remove people or objects. This process is strictly prohibited by OpenAI, but people do what people do.
Technology is moving fast. AI is becoming more a part of our lives and we are just on the cutting edge of it. DALL-E 2 is only the beginning, but it also has its eye on the future.